
English-Spanish Translation with Transformers
This project develops an English-Spanish translation model using transformer architectures. By training on a large corpus of parallel texts, the model achieves high accuracy and fluency. It involves data preprocessing, model training, and evaluation, showcasing the power of transformers in enhancing multilingual communication.
Sequence-to-sequence transformer to translate Spanish to English.
Project Walkthrough:
- Step 1. Data Preprocessing
- Downloading
- Parsing
- Vectorizing text using the Keras
TextVectorizationlayer. - Formatting data for training
- Step 2. Implement a Transformer
- A
PositionalEmbeddinglayer - A
TransformerEncoderlayer and aTransformerDecoderlayer - Sequence all layers together to build a
Transformermodel
- A
- Step 3. Train the model
- Step 4. Inference: Use the trained model to translate new sequences
Setup
import pathlib import random import string import re import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras.layers import TextVectorization
Step 1. Data Preprocessing
Downloading
First, download an English-to-Spanish translation dataset from Anki.
text_file = keras.utils.get_file( fname="spa-eng.zip", origin="http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip", extract=True, ) text_file = pathlib.Path(text_file).parent / "spa-eng" / "spa.txt"
Parsing
Each line contains an English sentence and its corresponding Spanish sentence. The English sentence is the source sequence and Spanish one is the target sequence. We prepend the token[start] and we append the token [end] to the Spanish sentence.
with open(text_file) as f: lines = f.read().split("\n")[:-1] text_pairs = [] for line in lines: eng, spa = line.split("\t") spa = "[start] " + spa + " [end]" text_pairs.append((eng, spa))
Here's what our sentence pairs look like:
for _ in range(5): print(random.choice(text_pairs))
('I think Tom is working now.', '[start] Creo que ahora Tomás trabaja. [end]')
("I'm very interested in classical literature.", '[start] Me interesa mucho la literatura clásica. [end]')
('I appreciate you.', '[start] Te tengo cariño. [end]')
('Do you want to watch this program?', '[start] ¿Quieres ver este programa? [end]')
('We just have to stick together.', '[start] Sólo tenemos que permanecer juntos. [end]')
Now, let's split the sentence pairs into a training set, a validation set, and a test set.
random.shuffle(text_pairs) num_train_samples = 1000 num_val_samples = 1000 num_test_samples = 1000 num_val_samples = int(0.15 * len(text_pairs)) num_train_samples = len(text_pairs) - 2 * num_val_samples num_test_samples = len(text_pairs) - num_val_samples - num_train_samples train_pairs = text_pairs[:num_train_samples] val_pairs = text_pairs[num_train_samples : num_train_samples + num_val_samples] test_pairs = text_pairs[num_train_samples + num_val_samples :] print(f"{len(text_pairs)} total pairs") print(f"{len(train_pairs)} training pairs") print(f"{len(val_pairs)} validation pairs") print(f"{len(test_pairs)} test pairs")
118964 total pairs
83276 training pairs
17844 validation pairs
17844 test pairs
Vectorizing the text data
A TextVectorization layer vectorizes the text data into integer sequences where each integer represents the index of a word in a vocabulary.
The English layer will use the default string standardization (strip punctuation characters) and splitting scheme (split on whitespace), while the Spanish layer will use a custom standardization, where we add the character ¿ to the set of punctuation characters to be stripped.
strip_chars = string.punctuation + "¿" strip_chars = strip_chars.replace("[", "") strip_chars = strip_chars.replace("]", "") vocab_size = 15000 sequence_length = 20 batch_size = 64 def custom_standardization(input_string): lowercase = tf.strings.lower(input_string) return tf.strings.regex_replace(lowercase, "[%s]" % re.escape(strip_chars), "") eng_vectorization = TextVectorization( max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length, ) spa_vectorization = TextVectorization( max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length + 1, standardize=custom_standardization, ) train_eng_texts = [pair[0] for pair in train_pairs] train_spa_texts = [pair[1] for pair in train_pairs] eng_vectorization.adapt(train_eng_texts) spa_vectorization.adapt(train_spa_texts)
Formating
Recall that at each training step, the model will seek to predict target words N+1 (and beyond) using the source sentence and the target words 0 to N. As such, the training dataset will yield a tuple(inputs, targets), where:
inputsis a dictionary with the keysencoder_inputsanddecoder_inputs.decoder_inputsis the vectorized source sentence andencoder_inputsis the target sentence "so far", that is to say, the words 0 to N used to predict word N+1 (and beyond) in the target sentence.targetis the target sentence offset by one step: it provides the next words in the target sentence -- what the model will try to predict.
def format_dataset(eng, spa): eng = eng_vectorization(eng) spa = spa_vectorization(spa) return ({"encoder_inputs": eng, "decoder_inputs": spa[:, :-1],}, spa[:, 1:]) def make_dataset(pairs): eng_texts, spa_texts = zip(*pairs) eng_texts = list(eng_texts) spa_texts = list(spa_texts) dataset = tf.data.Dataset.from_tensor_slices((eng_texts, spa_texts)) dataset = dataset.batch(batch_size) dataset = dataset.map(format_dataset) return dataset.shuffle(2048).prefetch(16).cache() train_ds = make_dataset(train_pairs) val_ds = make_dataset(val_pairs)
Let's take a quick look at the sequence shapes (we have batches of 64 pairs, and all sequences are 20 steps long):
for inputs, targets in train_ds.take(1): print(f'inputs["encoder_inputs"].shape: {inputs["encoder_inputs"].shape}') print(f'inputs["decoder_inputs"].shape: {inputs["decoder_inputs"].shape}') print(f"targets.shape: {targets.shape}")
inputs["encoder_inputs"].shape: (64, 20)
inputs["decoder_inputs"].shape: (64, 20)
targets.shape: (64, 20)
Step 2. Implement a Transformer
Transformer Overview
The input will first be passed to an embedding layer and a position embedding layer (we merge two layers into the
PositionalEmbedding Layer), to obtain embeddingsNext, the input embedding of the source sequence will be passed to the
TransformerEncoder, which will produce a new representation of it.This new representation will then be passed to the
TransformerDecoder, together with the target sequence so far (target words 0 to N). TheTransformerDecoderwill then seek to predict the next words in the target sequence (N+1 and beyond).
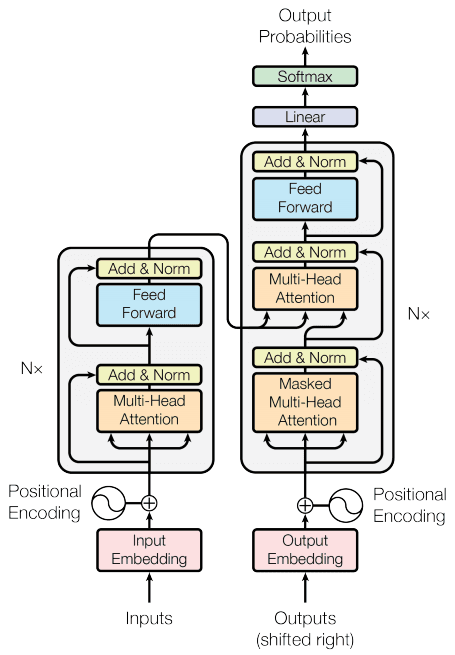
Figure 2: The Transformer architecture as discussed in lecture, from "Attention is all you need" (Vaswani et al., 2017).
Technical details
- The Transformer's encoder and decoder consist of N layers (
num_layers) each, containing multi-head attention (tf.keras.layers.MultiHeadAttention) layers with M heads (num_heads), and point-wise feed-forward networks.- The encoder leverages the self-attention mechanism.
- The decoder (with N decoder layers) attends to the encoder's output (with cross-attention to utilize the information from the encoder) and its own input (with masked self-attention) to predict the next word. The masked self-attention is causal—it is there to make sure the model can only rely on the preceding tokens in the decoding stage.
- Multi-head attention: Each multi-head attention block gets three inputs; Q (query), K (key), V (value). Instead of one single attention head, Q, K, and V are split into multiple heads because it allows the model to "jointly attend to information from different representation subspaces at different positions". You can read more about single-head-attention and multi-head-attention. The equation used to calculate the self-attention weights is as follows:
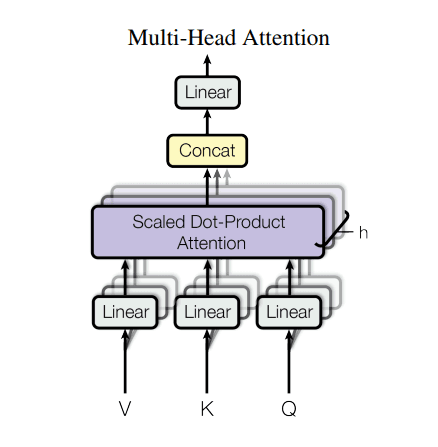
Figure 3: Multi-head attention from Google Research's "Attention is all you need"(Vaswani et al., 2017).
Component 1: Position Encoding Layer
After text vectorization, both the input sentences (English) and target sentences (Spanish) have to be converted to embedding vectors using a tf.keras.layers.Embedding layer. This purpose of the first embedding layer is to map word to a point in embedding space where similar words are closer to each other.
Next, a Transformer adds a Positional Encoding to the embedding vectors. In this exercise, we would use a set of sines and cosines at different frequencies (across the sequence). By definition, nearby elements will have similar position encodings.
We would use the following formula for calculating the positional encoding:
where pos takes value from 0 to length - 1and i takes value from 0 todepth/2.
def positional_encoding(length, depth): depth = depth/2 positions = np.arange(length)[:, np.newaxis] # (seq, 1) depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth) # compute angle_rads (angle in radians), the shape should be (pos, depth) angle_rads = positions / np.power(10_000, depths) pos_encoding = np.concatenate( [np.sin(angle_rads), np.cos(angle_rads)], axis=-1) return tf.cast(pos_encoding, dtype=tf.float32)
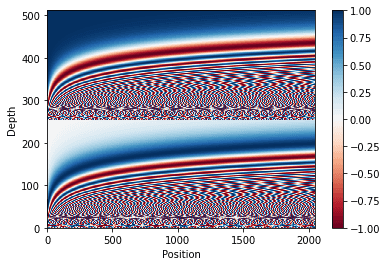
You can verify and view your implementation of position_encoding below.
import matplotlib.pyplot as plt pos_encoding = positional_encoding(length=2048, depth=512) assert pos_encoding.shape == (2048, 512) # Plot the dimensions. plt.pcolormesh(pos_encoding.numpy().T, cmap='RdBu') plt.ylabel('Depth') plt.xlabel('Position') plt.colorbar() plt.show()
Now, let's sequence the embedding and positional_encoding together to get a Positional Embedding Layer.
class PositionalEmbedding(layers.Layer): def __init__(self, sequence_length, vocab_size, embed_dim): super().__init__() self.sequence_length = sequence_length self.embed_dim = embed_dim self.embedding = tf.keras.layers.Embedding(vocab_size, embed_dim, mask_zero=True) self.pos_encoding = positional_encoding(length=sequence_length, depth=embed_dim) def compute_mask(self, *args, **kwargs): return self.embedding.compute_mask(*args, **kwargs) def call(self, x): length = tf.shape(x)[1] x = self.embedding(x) x *= tf.math.sqrt(tf.cast(self.embed_dim, tf.float32)) x = x + self.pos_encoding[tf.newaxis, :length, :] return x
Component 2: Encoder Layer
class TransformerEncoder(layers.Layer): def __init__(self, embed_dim, dense_dim, num_heads, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) self.embed_dim = embed_dim self.dense_dim = dense_dim self.num_heads = num_heads self.attention = layers.MultiHeadAttention( num_heads=num_heads, key_dim=embed_dim ) self.feed_forward = keras.Sequential( [layers.Dense(dense_dim, activation="relu"), layers.Dense(embed_dim),] ) self.layernorm_1 = layers.LayerNormalization() self.layernorm_2 = layers.LayerNormalization() self.supports_masking = True def call(self, inputs, mask=None): if mask is not None: padding_mask = tf.cast(mask[:, tf.newaxis, tf.newaxis, :], dtype="int32") else: padding_mask = None attention_output = self.attention(query = inputs, value = inputs, key = inputs, attention_mask = padding_mask) proj_input = self.layernorm_1(inputs + attention_output) proj_output = self.feed_forward(proj_input) encoder_output = self.layernorm_2(proj_input + proj_output) return encoder_output def get_config(self): config = super().get_config() config.update({ "embed_dim": self.embed_dim, "dense_dim": self.dense_dim, "num_heads": self.num_heads, }) return config class TransformerDecoder(layers.Layer): def __init__(self, embed_dim, latent_dim, num_heads, **kwargs): super(TransformerDecoder, self).__init__(**kwargs) self.embed_dim = embed_dim self.latent_dim = latent_dim self.num_heads = num_heads self.attention_1 = layers.MultiHeadAttention( num_heads=num_heads, key_dim=embed_dim ) self.attention_2 = layers.MultiHeadAttention( num_heads=num_heads, key_dim=embed_dim ) self.feed_forward = keras.Sequential( [layers.Dense(latent_dim, activation="relu"), layers.Dense(embed_dim),] ) self.layernorm_1 = layers.LayerNormalization() self.layernorm_2 = layers.LayerNormalization() self.layernorm_3 = layers.LayerNormalization() self.supports_masking = True def call(self, inputs, encoder_outputs, mask=None): causal_mask = self.get_causal_attention_mask(inputs) if mask is not None: padding_mask = tf.cast(mask[:, tf.newaxis, :], dtype="int32") padding_mask = tf.minimum(padding_mask, causal_mask) attention_output_1 = self.attention_1(query = inputs, value = inputs, key = inputs, attention_mask = causal_mask) out_1 = self.layernorm_1(inputs + attention_output_1) attention_output_2 = self.attention_2(query = out_1, value = encoder_outputs, key = encoder_outputs, attention_mask = padding_mask) out_2 = self.layernorm_2(out_1 + attention_output_2) proj_output = self.feed_forward(out_2) decoder_output = self.layernorm_3(out_2 + proj_output) return decoder_output def get_causal_attention_mask(self, inputs): input_shape = tf.shape(inputs) batch_size, sequence_length = input_shape[0], input_shape[1] i = tf.range(sequence_length)[:, tf.newaxis] j = tf.range(sequence_length) mask = tf.cast(i >= j, dtype="int32") mask = tf.reshape(mask, (1, input_shape[1], input_shape[1])) mult = tf.concat( [tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)], axis=0, ) return tf.tile(mask, mult) def get_config(self): config = super().get_config() config.update({ "embed_dim": self.embed_dim, "latent_dim": self.latent_dim, "num_heads": self.num_heads, }) return config
Component 3: Assemble the end-to-end model
Define the hyper-parameters
embed_dim = 64 #256 latent_dim = 512 #2048 num_heads = 4 #
Assemble the layers
encoder_inputs = keras.Input(shape=(None,), dtype="int64", name="encoder_inputs") x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(encoder_inputs) encoder_outputs = TransformerEncoder(embed_dim, latent_dim, num_heads)(x) encoder = keras.Model(encoder_inputs, encoder_outputs) decoder_inputs = keras.Input(shape=(None,), dtype="int64", name="decoder_inputs") encoded_seq_inputs = keras.Input(shape=(None, embed_dim), name="decoder_state_inputs") x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(decoder_inputs) x = TransformerDecoder(embed_dim, latent_dim, num_heads)(x, encoded_seq_inputs) x = tf.keras.layers.Dropout(0.5)(x) decoder_outputs = tf.keras.layers.Dense(units = vocab_size, activation = "softmax")(x) # Note: the goal of this layer is to expand the dimension to match the vocabulary size in the target language, so choosing the layer output size accordingly # Note: the output should be probabilities, so choose the activation function accordingly. decoder = keras.Model([decoder_inputs, encoded_seq_inputs], decoder_outputs) decoder_outputs = decoder([decoder_inputs, encoder_outputs]) transformer = keras.Model( [encoder_inputs, decoder_inputs], decoder_outputs, name="transformer" )
Step 3. Training our model
We'll use accuracy as a quick way to monitor training progress on the validation data. Note that machine translation typically uses BLEU scores as well as other metrics, rather than accuracy. Here we only train for a few epochs (to confirm everything), but to get the model to actually converge you should train for at least 30 epochs.
Model: "transformer"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_inputs (InputLayer) [(None, None)] 0 []
positional_embedding_4 (Positi (None, None, 64) 960000 ['encoder_inputs[0][0]']
onalEmbedding)
decoder_inputs (InputLayer) [(None, None)] 0 []
transformer_encoder_2 (Transfo (None, None, 64) 132736 ['positional_embedding_4[0][0]']
rmerEncoder)
model_5 (Functional) (None, None, 15000) 2134232 ['decoder_inputs[0][0]',
'transformer_encoder_2[0][0]
']
==================================================================================================
Total params: 3,226,968
Trainable params: 3,226,968
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/30
1302/1302 [==============================] - 53s 38ms/step - loss: 1.8328 - accuracy: 0.3688 - val_loss: 1.4703 - val_accuracy: 0.4539
Epoch 2/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.5145 - accuracy: 0.4660 - val_loss: 1.3097 - val_accuracy: 0.5182
Epoch 3/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.3744 - accuracy: 0.5148 - val_loss: 1.2292 - val_accuracy: 0.5565
Epoch 4/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.2884 - accuracy: 0.5498 - val_loss: 1.1951 - val_accuracy: 0.5806
Epoch 5/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.2442 - accuracy: 0.5725 - val_loss: 1.1687 - val_accuracy: 0.5936
Epoch 6/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.2200 - accuracy: 0.5878 - val_loss: 1.1617 - val_accuracy: 0.5999
Epoch 7/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.2036 - accuracy: 0.5994 - val_loss: 1.1558 - val_accuracy: 0.6052
Epoch 8/30
1302/1302 [==============================] - 49s 37ms/step - loss: 1.1902 - accuracy: 0.6091 - val_loss: 1.1535 - val_accuracy: 0.6095
Epoch 9/30
1302/1302 [==============================] - 49s 38ms/step - loss: 1.1810 - accuracy: 0.6168 - val_loss: 1.1555 - val_accuracy: 0.6116
Epoch 10/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1715 - accuracy: 0.6228 - val_loss: 1.1543 - val_accuracy: 0.6142
Epoch 11/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1624 - accuracy: 0.6288 - val_loss: 1.1536 - val_accuracy: 0.6150
Epoch 12/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1530 - accuracy: 0.6336 - val_loss: 1.1583 - val_accuracy: 0.6144
Epoch 13/30
1302/1302 [==============================] - 49s 38ms/step - loss: 1.1453 - accuracy: 0.6377 - val_loss: 1.1535 - val_accuracy: 0.6178
Epoch 14/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1371 - accuracy: 0.6416 - val_loss: 1.1585 - val_accuracy: 0.6178
Epoch 15/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1301 - accuracy: 0.6446 - val_loss: 1.1570 - val_accuracy: 0.6172
Epoch 16/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1235 - accuracy: 0.6478 - val_loss: 1.1561 - val_accuracy: 0.6190
Epoch 17/30
1302/1302 [==============================] - 48s 37ms/step - loss: 1.1166 - accuracy: 0.6503 - val_loss: 1.1526 - val_accuracy: 0.6216
Step 4. Inference: use the trained model to translate new sequences.
Decoding test sentences
Finally, let's demonstrate how to translate brand new English sentences. We simply feed into the model the vectorized English sentence as well as the target token [start], then we repeatedly generated the next token, until we hit the token[end].
spa_vocab = spa_vectorization.get_vocabulary() spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab)) max_decoded_sentence_length = 20 def decode_sequence(input_sentence): tokenized_input_sentence = eng_vectorization([input_sentence]) decoded_sentence = "[start]" for i in range(max_decoded_sentence_length): tokenized_target_sentence = spa_vectorization([decoded_sentence])[:, :-1] probs = transformer([tokenized_input_sentence, tokenized_target_sentence], training = False) sampled_token_index = int(np.argmax(probs[:, i, :], 1)) sampled_token = spa_index_lookup[sampled_token_index] decoded_sentence += " " + sampled_token if sampled_token == "[end]": break return decoded_sentence test_eng_texts = [pair[0] for pair in test_pairs] for _ in range(30): input_sentence = random.choice(test_eng_texts) translated = decode_sequence(input_sentence) print("{}-->{}".format(input_sentence, translated))
After 30 epochs, we get results such as:
She handed him the money. [start] ella le pasó el dinero [end]
Tom has never heard Mary sing. [start] tom nunca ha oído cantar a mary [end]
Perhaps she will come tomorrow. [start] tal vez ella vendrá mañana [end]
I love to write. [start] me encanta escribir [end]
His French is improving little by little. [start] su francés va a [UNK] sólo un poco [end]
My hotel told me to call you. [start] mi hotel me dijo que te [UNK] [end]